6.14 其它操作
成对的数据操作有 list 与 unlist、stack 与 unstack、class 与 unclass、attach 与 detach 以及 with 和 within,它们在数据操作过程中有时会起到一定的补充作用。
6.14.1 列表属性
# 创建列表
list(...)
pairlist(...)
# 转化列表
as.list(x, ...)
## S3 method for class 'environment'
as.list(x, all.names = FALSE, sorted = FALSE, ...)
as.pairlist(x)
# 检查列表
is.list(x)
is.pairlist(x)
alist(...)list 函数用来构造、转化和检查 R 列表对象。下面创建一个临时列表对象 tmp ,它包含两个元素 A 和 B,两个元素都是向量,前者是数值型,后者是字符型
(tmp <- list(A = c(1, 2, 3), B = c("a", "b")))## $A
## [1] 1 2 3
##
## $B
## [1] "a" "b"unlist(x, recursive = TRUE, use.names = TRUE)unlist 函数将给定的列表对象 x 简化为原子向量 (atomic vector),我们发现简化之后变成一个字符型向量
unlist(tmp)## A1 A2 A3 B1 B2
## "1" "2" "3" "a" "b"unlist(tmp, use.names = FALSE)## [1] "1" "2" "3" "a" "b"unlist 的逆操作是 relist
6.14.2 堆叠向量
stack(x, ...)
## Default S3 method:
stack(x, drop = FALSE, ...)
## S3 method for class 'data.frame'
stack(x, select, drop = FALSE, ...)
unstack(x, ...)
## Default S3 method:
unstack(x, form, ...)
## S3 method for class 'data.frame'
unstack(x, form, ...)stack 与 unstack 将多个向量堆在一起组成一个向量
# 查看数据集 PlantGrowth
class(PlantGrowth)## [1] "data.frame"head(PlantGrowth)## weight group
## 1 4.17 ctrl
## 2 5.58 ctrl
## 3 5.18 ctrl
## 4 6.11 ctrl
## 5 4.50 ctrl
## 6 4.61 ctrl# 检查默认的公式
formula(PlantGrowth) ## weight ~ group# 根据公式解除堆叠
# 下面等价于 unstack(PlantGrowth, form = weight ~ group)
(pg <- unstack(PlantGrowth)) ## ctrl trt1 trt2
## 1 4.17 4.81 6.31
## 2 5.58 4.17 5.12
## 3 5.18 4.41 5.54
## 4 6.11 3.59 5.50
## 5 4.50 5.87 5.37
## 6 4.61 3.83 5.29
## 7 5.17 6.03 4.92
## 8 4.53 4.89 6.15
## 9 5.33 4.32 5.80
## 10 5.14 4.69 5.26现在再将变量 pg 堆叠起来,还可以指定要堆叠的列
stack(pg)## values ind
## 1 4.17 ctrl
## 2 5.58 ctrl
## 3 5.18 ctrl
## 4 6.11 ctrl
## 5 4.50 ctrl
....stack(pg, select = -ctrl)## values ind
## 1 4.81 trt1
## 2 4.17 trt1
## 3 4.41 trt1
## 4 3.59 trt1
## 5 5.87 trt1
....6.14.3 属性转化
class(x)
class(x) <- value
unclass(x)
inherits(x, what, which = FALSE)
oldClass(x)
oldClass(x) <- valueclass 和 unclass 函数用来查看、设置类属性和取消类属性,常用于面向对象的编程设计中
class(iris)## [1] "data.frame"class(iris$Species)## [1] "factor"unclass(iris$Species)## [1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [38] 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
## [75] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 3
## [112] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
## [149] 3 3
## attr(,"levels")
....6.14.4 绑定环境
attach(what,
pos = 2L, name = deparse(substitute(what), backtick = FALSE),
warn.conflicts = TRUE
)
detach(name,
pos = 2L, unload = FALSE, character.only = FALSE,
force = FALSE
)attach 和 detach 是否绑定数据框的列名,不推荐操作,推荐使用 with
attach(iris)
head(Species)## [1] setosa setosa setosa setosa setosa setosa
## Levels: setosa versicolor virginicadetach(iris)6.14.5 数据环境
with(data, expr, ...)
within(data, expr, ...)
## S3 method for class 'list'
within(data, expr, keepAttrs = TRUE, ...)data- 参数
data用来构造表达式计算的环境。其默认值可以是一个环境,列表,数据框。在within函数中data参数只能是列表或数据框。 expr参数
expr包含要计算的表达式。在within中通常包含一个复合表达式,比如{ a <- somefun() b <- otherfun() ... rm(unused1, temp) }
with 和 within 计算一组表达式,计算的环境是由数据构造的,后者可以修改原始的数据
with(mtcars, mpg[cyl == 8 & disp > 350])## [1] 18.7 14.3 10.4 10.4 14.7 19.2 15.8和下面计算的结果一样,但是更加简洁漂亮
mtcars$mpg[mtcars$cyl == 8 & mtcars$disp > 350]## [1] 18.7 14.3 10.4 10.4 14.7 19.2 15.8within 函数可以修改原数据环境中的多个变量,比如删除、修改和添加等
# 原数据集 airquality
head(airquality)## Ozone Solar.R Wind Temp Month Day
## 1 41 190 7.4 67 5 1
## 2 36 118 8.0 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 6aq <- within(airquality, {
lOzone <- log(Ozone) # 取对数
Month <- factor(month.abb[Month]) # 字符串型转因子型
cTemp <- round((Temp - 32) * 5 / 9, 1) # 从华氏温度到摄氏温度转化
S.cT <- Solar.R / cTemp # 使用新创建的变量
rm(Day, Temp)
})
# 修改后的数据集
head(aq)## Ozone Solar.R Wind Month S.cT cTemp lOzone
## 1 41 190 7.4 May 9.793814 19.4 3.713572
## 2 36 118 8.0 May 5.315315 22.2 3.583519
## 3 12 149 12.6 May 6.394850 23.3 2.484907
## 4 18 313 11.5 May 18.742515 16.7 2.890372
## 5 NA NA 14.3 May NA 13.3 NA
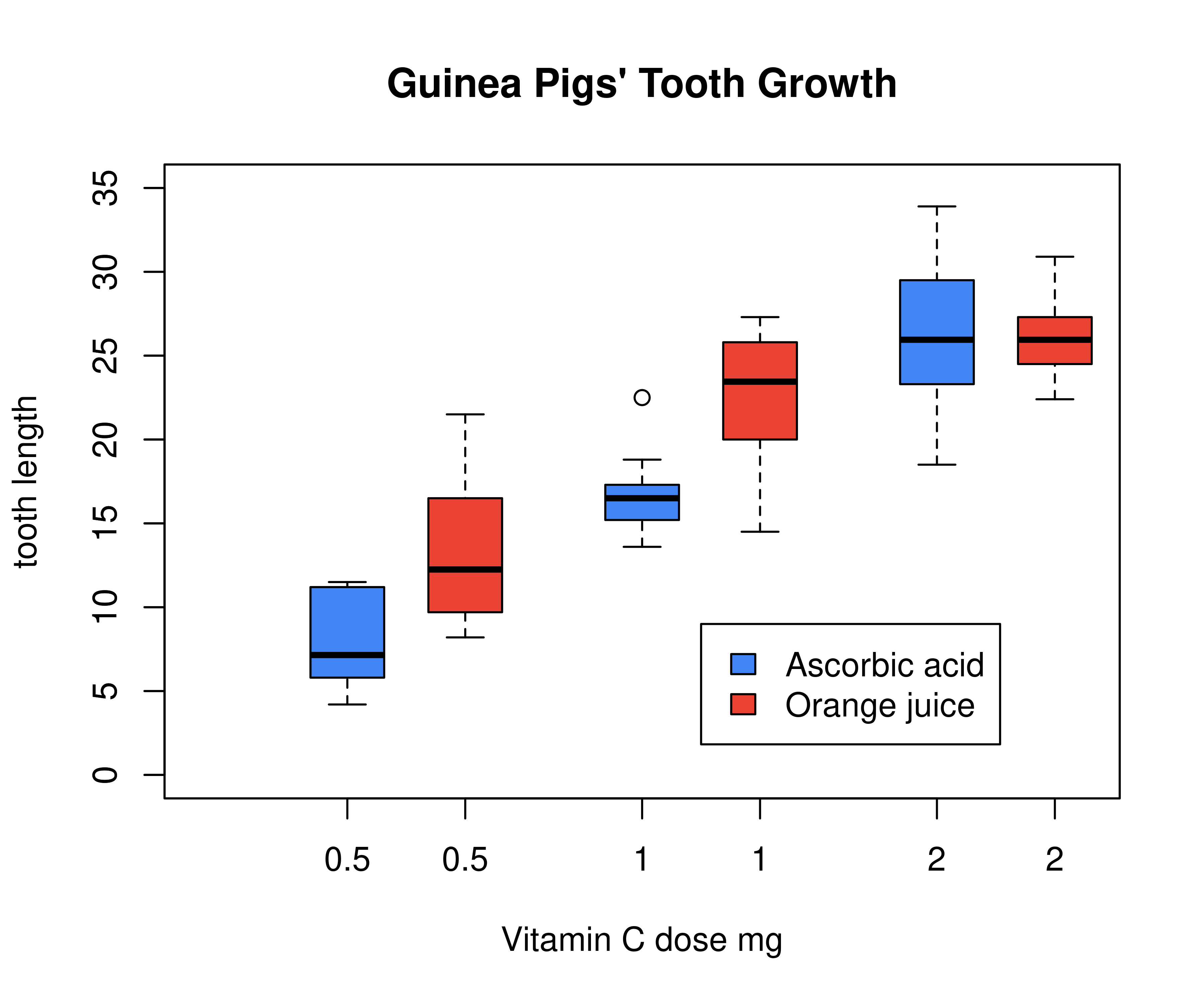
## 6 28 NA 14.9 May NA 18.9 3.332205下面再举一个复杂的绘图例子,这个例子来自 boxplot 函数
with(ToothGrowth, {
boxplot(len ~ dose,
boxwex = 0.25, at = 1:3 - 0.2,
subset = (supp == "VC"), col = "#4285f4",
main = "Guinea Pigs' Tooth Growth",
xlab = "Vitamin C dose mg",
ylab = "tooth length", ylim = c(0, 35)
)
boxplot(len ~ dose,
add = TRUE, boxwex = 0.25, at = 1:3 + 0.2,
subset = supp == "OJ", col = "#EA4335"
)
legend(2, 9, c("Ascorbic acid", "Orange juice"),
fill = c("#4285f4", "#EA4335")
)
})
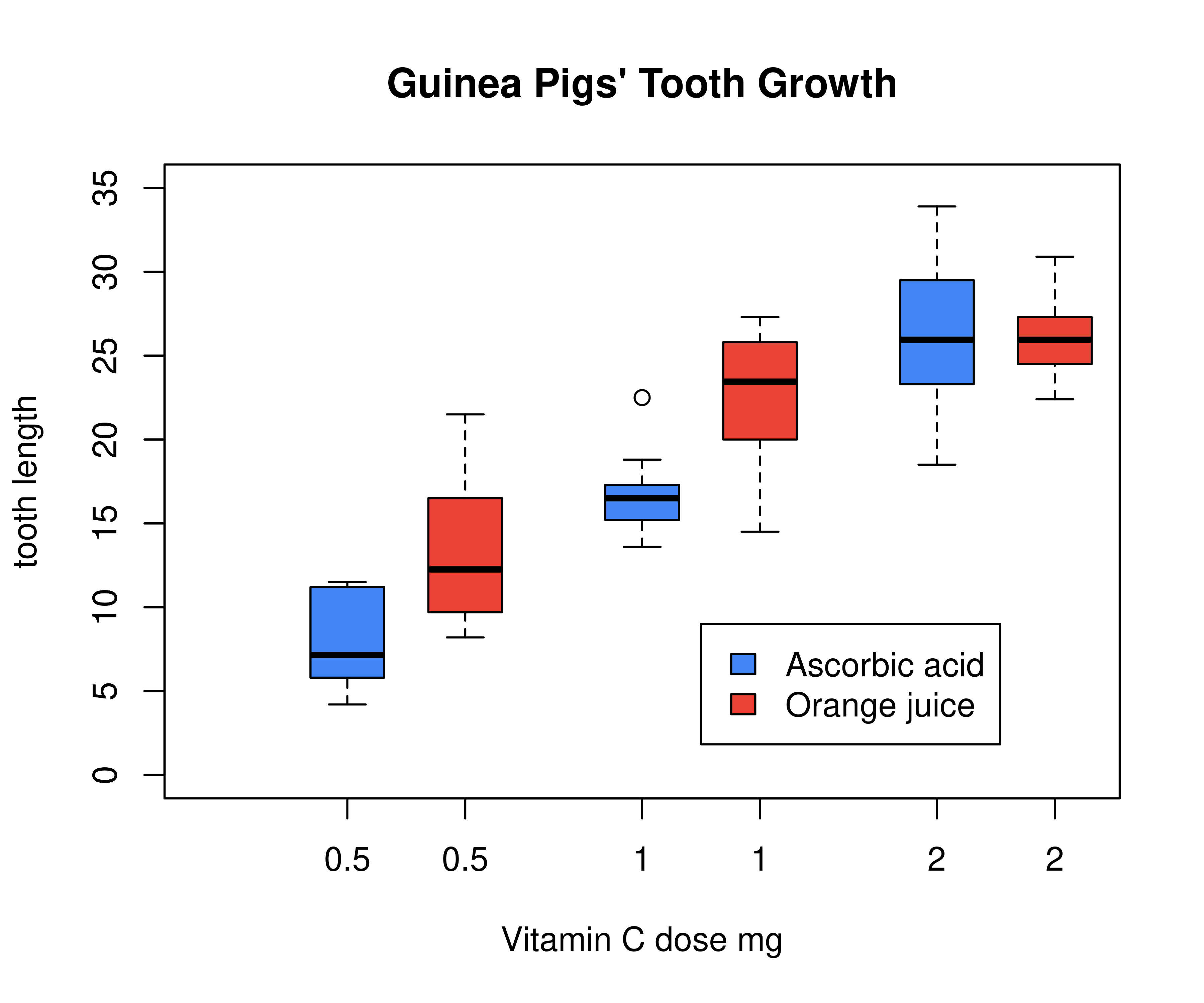
将 boxplot 函数的 subset 参数单独提出来,调用数据子集选择函数 subset ,这里 with 中只包含一个表达式,所以也可以不用大括号
with(
subset(ToothGrowth, supp == "VC"),
boxplot(len ~ dose,
boxwex = 0.25, at = 1:3 - 0.2,
col = "#4285f4", main = "Guinea Pigs' Tooth Growth",
xlab = "Vitamin C dose mg",
ylab = "tooth length", ylim = c(0, 35)
)
)
with(
subset(ToothGrowth, supp == "OJ"),
boxplot(len ~ dose,
add = TRUE, boxwex = 0.25, at = 1:3 + 0.2,
col = "#EA4335"
)
)
legend(2, 9, c("Ascorbic acid", "Orange juice"),
fill = c("#4285f4", "#EA4335")
)
可以作为数据变换 transform 的一种替代,它也比较像 dplyr 包的 mutate 函数
within(mtcars[1:5,1:3],{
disp.cc <- disp * 2.54^3
disp.l <- disp.cc / 1e3
})## mpg cyl disp disp.l disp.cc
## Mazda RX4 21.0 6 160 2.621930 2621.930
## Mazda RX4 Wag 21.0 6 160 2.621930 2621.930
## Datsun 710 22.8 4 108 1.769803 1769.803
## Hornet 4 Drive 21.4 6 258 4.227863 4227.863
## Hornet Sportabout 18.7 8 360 5.899343 5899.343# 只能使用已有的列,刚生成的列不能用
# transform(
# mtcars[1:5, 1:3],
# disp.cc = disp * 2.54^3,
# disp.l = disp.cc / 1e3
# )
transform(
mtcars[1:5, 1:3],
disp.cc = disp * 2.54^3
)## mpg cyl disp disp.cc
## Mazda RX4 21.0 6 160 2621.930
## Mazda RX4 Wag 21.0 6 160 2621.930
## Datsun 710 22.8 4 108 1769.803
## Hornet 4 Drive 21.4 6 258 4227.863
## Hornet Sportabout 18.7 8 360 5899.343transform 只能使用已有的列,变换中间生成的列不能用,所以相比于 transform 函数, within 显得更为灵活