3.4 从数据库导入
Hands-On Programming with R 数据读写章节7 以及 R, Databases and Docker
将大量的 txt 文本存进 MySQL 数据库中,通过操作数据库来聚合文本,极大降低内存消耗 8,而 ODBC 与 DBI 包是其它数据库接口的基础,knitr 提供了一个支持 SQL 代码的引擎,它便是基于 DBI,因此可以在 R Markdown 文档中直接使用 SQL 代码块 9。这里制作一个归纳表格,左边数据库右边对应其 R 接口,两边都包含链接,如表 3.4 所示
| 数据库 | 官网 | R接口 | 开发仓 |
|---|---|---|---|
| MySQL | https://www.mysql.com/ | RMySQL | https://github.com/r-dbi/RMySQL |
| SQLite | https://www.sqlite.org | RSQLite | https://github.com/r-dbi/RSQLite |
| PostgreSQL | https://www.postgresql.org/ | RPostgres | https://github.com/r-dbi/RPostgres |
| MariaDB | https://mariadb.org/ | RMariaDB | https://github.com/r-dbi/RMariaDB |
3.4.1 PostgreSQL
odbc 可以支持很多数据库,下面以连接 PostgreSQL 数据库为例介绍其过程
首先在某台机器上,拉取 PostgreSQL 的 Docker 镜像
docker pull postgres在 Docker 上运行 PostgreSQL,主机端口号 8181 映射给数据库 PostgreSQL 的默认端口号 5432(或其它你的 DBA 分配给你的端口)
docker run --name psql -d -p 8181:5432 -e ROOT=TRUE \
-e USER=xiangyun -e PASSWORD=cloud postgres在主机 Ubuntu 上配置
sudo apt-get install unixodbc unixodbc-dev odbc-postgresql端口 5432 是分配给 PostgreSQL 的默认端口,host 可以是云端的地址,如 你的亚马逊账户下的 PostgreSQL 数据库地址 <ec2-54-83-201-96.compute-1.amazonaws.com>,也可以是本地局域网IP地址,如<192.168.1.200>。通过参数 dbname 连接到指定的 PostgreSQL 数据库,如 Heroku,这里作为演示就以默认的数据库 postgres 为例
查看配置系统文件路径
odbcinst -j unixODBC 2.3.6
DRIVERS............: /etc/odbcinst.ini
SYSTEM DATA SOURCES: /etc/odbc.ini
FILE DATA SOURCES..: /etc/ODBCDataSources
USER DATA SOURCES..: /root/.odbc.ini
SQLULEN Size.......: 8
SQLLEN Size........: 8
SQLSETPOSIROW Size.: 8不推荐修改全局配置文件,可设置 ODBCSYSINI 环境变量指定配置文件路径,如 ODBCSYSINI=~/ODBC http://www.unixodbc.org/odbcinst.html
安装完驱动程序,/etc/odbcinst.ini 文件内容自动更新,我们可以不必修改,如果你想自定义不妨手动修改,我们查看在 R 环境中注册的数据库,可以看到 PostgreSQL 的驱动已经配置好
odbc::odbcListDrivers() name attribute value
1 PostgreSQL ANSI Description PostgreSQL ODBC driver (ANSI version)
2 PostgreSQL ANSI Driver psqlodbca.so
3 PostgreSQL ANSI Setup libodbcpsqlS.so
4 PostgreSQL ANSI Debug 0
5 PostgreSQL ANSI CommLog 1
6 PostgreSQL ANSI UsageCount 1
7 PostgreSQL Unicode Description PostgreSQL ODBC driver (Unicode version)
8 PostgreSQL Unicode Driver psqlodbcw.so
9 PostgreSQL Unicode Setup libodbcpsqlS.so
10 PostgreSQL Unicode Debug 0
11 PostgreSQL Unicode CommLog 1
12 PostgreSQL Unicode UsageCount 1系统配置文件 /etc/odbcinst.ini 已经包含有 PostgreSQL 的驱动配置,无需再重复配置
[PostgreSQL ANSI]
Description=PostgreSQL ODBC driver (ANSI version)
Driver=psqlodbca.so
Setup=libodbcpsqlS.so
Debug=0
CommLog=1
UsageCount=1
[PostgreSQL Unicode]
Description=PostgreSQL ODBC driver (Unicode version)
Driver=psqlodbcw.so
Setup=libodbcpsqlS.so
Debug=0
CommLog=1
UsageCount=1只需将如下内容存放在 ~/.odbc.ini 文件中,
[PostgreSQL]
Driver = PostgreSQL Unicode
Database = postgres
Servername = 172.17.0.1
UserName = postgres
Password = default
Port = 8080最后,一行命令 DNS 配置连接 https://github.com/r-dbi/odbc 这样就实现了代码中无任何敏感信息,这里为了展示这个配置过程故而把相关信息公开。
注意下面的内容需要在容器中运行, Windows 环境下的配置 PostgreSQL 的驱动有点麻烦就不搞了,意义也不大,现在数据库基本都是跑在 Linux 系统上
docker-machine.exe ip default 可以获得本地 Docker 的 IP,比如 192.168.99.101。 Travis 上 ip addr 可以查看 Docker 的 IP,如 172.17.0.1
library(DBI)
con <- dbConnect(RPostgres::Postgres(),
dbname = "postgres",
host = ifelse(is_on_travis, Sys.getenv("DOCKER_HOST_IP"), "192.168.99.101"),
port = 8080,
user = "postgres",
password = "default"
)library(DBI)
con <- dbConnect(odbc::odbc(), "PostgreSQL")列出数据库中的所有表
dbListTables(con)第一次启动从 Docker Hub 上下载的镜像,默认的数据库是 postgres 里面没有任何表,所以将 R 环境中的 mtcars 数据集写入 postgres 数据库
将数据集 mtcars 写入 PostgreSQL 数据库中,基本操作,写入表的操作也不能缓存,即不能缓存数据库中的表 mtcars
dbWriteTable(con, "mtcars", mtcars, overwrite = TRUE)现在可以看到数据表 mtcars 的各个字段
dbListFields(con, "mtcars")最后执行一条 SQL 语句
res <- dbSendQuery(con, "SELECT * FROM mtcars WHERE cyl = 4") # 发送 SQL 语句
dbFetch(res) # 获取查询结果
dbClearResult(res) # 清理查询通道或者一条命令搞定
dbGetQuery(con, "SELECT * FROM mtcars WHERE cyl = 4")再复杂一点的 SQL 查询操作
dbGetQuery(con, "SELECT cyl, AVG(mpg) AS mpg FROM mtcars GROUP BY cyl ORDER BY cyl")
aggregate(mpg ~ cyl, data = mtcars, mean)得益于 knitr [3] 开发的钩子,这里直接写 SQL 语句块,值得注意的是 SQL 代码块不能启用缓存,数据库连接通道也不能缓存,如果数据库中还没有写入表,那么写入表的操作也不能缓存, tab.cap = "表格标题" 输出的内容是一个表格
SELECT cyl, AVG(mpg) AS mpg FROM mtcars GROUP BY cyl ORDER BY cyl如果将查询结果导出到变量,在 Chunk 设置 output.var = "agg_cyl" 可以使用缓存,下面将 mpg 按 cyl 分组聚合的结果打印出来,ref.label = "mtcars" 引用上一个 SQL 代码块的内容
这种基于 odbc 的方式的好处就不需要再安装 R 包 RPostgres 和相关系统依赖,最后关闭连接通道
dbDisconnect(con)3.4.2 MySQL
MySQL 是一个很常见,应用也很广泛的数据库,数据分析的常见环境是在一个R Notebook 里,我们可以在正文之前先设定数据库连接信息
```{r setup}
library(DBI)
# 指定数据库连接信息
db <- dbConnect(RMySQL::MySQL(),
dbname = 'dbtest',
username = 'user_test',
password = 'password',
host = '10.10.101.10',
port = 3306
)
# 创建默认连接
knitr::opts_chunk$set(connection = 'db')
# 设置字符编码,以免中文查询乱码
DBI::dbSendQuery(db, 'SET NAMES utf8')
# 设置日期变量,以运用在SQL中
idate <- '2019-05-03'
```SQL 代码块中使用 R 环境中的变量,并将查询结果输出为R环境中的数据框
```{sql, output.var='data_output'}
SELECT * FROM user_table where date_format(created_date,'%Y-%m-%d')>=?idate
```以上代码会将 SQL 的运行结果存在 data_output 这是数据库中,idate 取之前设置的日期2019-05-03,user_table 是 MySQL 数据库中的表名,created_date 是创建user_table时,指定的日期名。
如果 SQL 比较长,为了代码美观,把带有变量的 SQL 保存为demo.sql脚本,只需要在 SQL 的 chunk 中直接读取 SQL 文件10。
```{sql, code=readLines('demo.sql'), output.var='data_output'}
```如果我们需要每天或者按照指定的日期重复地运行这个 R Markdown 文件,可以在 YAML 部分引入参数11
---
params:
date: "2019-05-03" # 参数化日期
---```{r setup, include=FALSE}
idate = params$date # 将参数化日期传递给 idate 变量
```我们将这个 Rmd 文件命名为 MyDocument.Rmd,运行这个文件可以从 R 控制台执行或在 RStudio 点击 knit。
rmarkdown::render("MyDocument.Rmd", params = list(
date = "2019-05-03"
))如果在文档的 YAML 位置已经指定日期,这里可以不指定。注意在这里设置日期会覆盖 YAML 处指定的参数值,这样做的好处是可以批量化操作。
3.4.3 Spark
当数据分析报告遇上 Spark 时,就需要 SparkR、 sparklyr、 arrow 或 rsparking 接口了, Javier Luraschi 写了一本书 The R in Spark: Learning Apache Spark with R 详细介绍了相关扩展和应用
首先安装 sparklyr 包,RStudio 公司 Javier Lurasch 开发了 sparklyr 包,作为 Spark 与 R 语言之间的接口,安装完 sparklyr 包,还是需要 Spark 和 Hadoop 环境
install.packages('sparklyr')
library(sparklyr)
spark_install()
# Installing Spark 2.4.0 for Hadoop 2.7 or later.
# Downloading from:
# - 'https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz'
# Installing to:
# - '~/spark/spark-2.4.0-bin-hadoop2.7'
# trying URL 'https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz'
# Content type 'application/x-gzip' length 227893062 bytes (217.3 MB)
# ==================================================
# downloaded 217.3 MB
#
# Installation complete.既然 sparklyr 已经安装了 Spark 和 Hadoop 环境,安装 SparkR 后,只需配置好路径,就可以加载 SparkR 包
install.packages('SparkR')
if (nchar(Sys.getenv("SPARK_HOME")) < 1) {
Sys.setenv(SPARK_HOME = "~/spark/spark-2.4.0-bin-hadoop2.7")
}
library(SparkR, lib.loc = c(file.path(Sys.getenv("SPARK_HOME"), "R", "lib")))
sparkR.session(master = "local[*]", sparkConfig = list(spark.driver.memory = "2g"))rscala 架起了 R 和 Scala 两门语言之间交流的桥梁,使得彼此之间可以互相调用
是否存在这样的可能, Spark 提供了大量的 MLib 库的调用接口,R 的功能支持是最少的,Java/Scala 是原生的,那么要么自己开发新的功能整合到 SparkR 中,要么借助 rscala 将 scala 接口代码封装进来
在本地,Windows 主机上,可以在 .Rprofile 中给 Spark 添加环境变量 SPARK_HOME 指定其安装路径,
# Windows 平台默认安装路径
Sys.setenv(SPARK_HOME = "C:/Users/XiangYun/AppData/Local/spark/spark-2.4.3-bin-hadoop2.7")
library(sparklyr)
sc <- spark_connect(master = "local", version = "2.4")将 R 环境中的数据集 mtcars 传递到 Spark 上
cars <- copy_to(sc, mtcars)
cars# Source: spark<mtcars> [?? x 11]
mpg cyl disp hp drat wt qsec vs am gear carb
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 21 6 160 110 3.9 2.62 16.5 0 1 4 4
2 21 6 160 110 3.9 2.88 17.0 0 1 4 4
3 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1
4 21.4 6 258 110 3.08 3.22 19.4 1 0 3 1
5 18.7 8 360 175 3.15 3.44 17.0 0 0 3 2
6 18.1 6 225 105 2.76 3.46 20.2 1 0 3 1
# ... with more rows监控和分析命令执行的情况,可以在浏览器中,见图 3.1
spark_web(sc)
图 3.1: Spark Web 接口
传递 SQL 查询语句,比如数据集 mtcars 有多少行
library(DBI)
dbGetQuery(sc, "SELECT count(*) FROM mtcars") count(1)
1 32进一步地,我们可以调用 dplyr 包来写数据操作,避免写复杂逻辑的 SQL 语句,
# library(dplyr) # 数据操作
library(tidyverse) # 提供更多功能,包括数据可视化
count(cars)再举一个稍复杂的操作,先从数据集 cars 中选择两个字段 hp 和 mpg
select(cars, hp, mpg) %>%
sample_n(100) |> # 随机选择 100 行
collect() |> # 执行 SQL 查询,将结果返回到本地
ggplot(aes(hp, mpg)) + # 绘图
geom_point()数据查询和结果可视化,见图 3.2
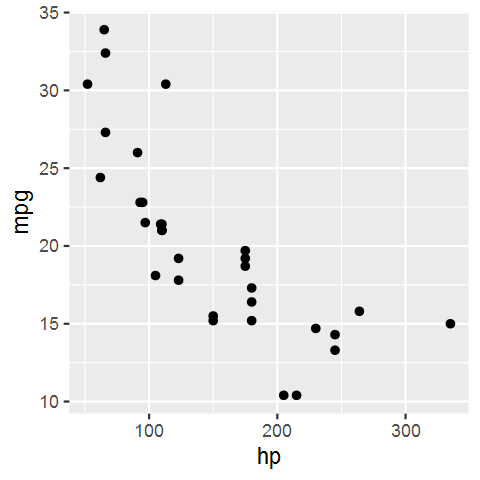
图 3.2: 数据聚合和可视化
用完要记得关闭连接
spark_disconnect(sc)不要使用 SparkR 接口,要使用 sparklyr, 后者的功能已经全面覆盖前者,生态方面更是更是已经远远超越,它有大厂 RStudio 支持,是公司支持的旗舰项目。但是 sparklyr 的版本稍微比最新的 Spark 低一两个版本,这是开发周期和出于稳定性的考虑,无伤大雅!
Spark 提供了官方 R 语言接口 SparkR。Spark JVM 和 SparkR 包版本要匹配,比如从 CRAN 上安装了最新版的 SparkR,比如版本 2.4.4 就要去 Spark 官网下载最新版的预编译文件 spark-2.4.4-bin-hadoop2.7,解压到本地磁盘,比如 D:/spark-2.4.4-bin-hadoop2.7
Sys.setenv(SPARK_HOME = "D:/spark-2.4.4-bin-hadoop2.7")
# Sys.setenv(R_HOME = "C:/Program Files/R/R-3.6.1/")
library(SparkR, lib.loc = c(file.path(Sys.getenv("SPARK_HOME"), "R", "lib")))
sparkR.session(master = "local[*]",
sparkConfig = list(spark.driver.memory = "4g"),
enableHiveSupport = TRUE)从数据集 mtcars(数据类型是 R 的 data.frame) 创建 Spark 的 DataFrame 类型数据
cars <- as.DataFrame(mtcars)
# 显示 SparkDataFrame 的前几行
head(cars) mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
4 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
5 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
6 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1打印数据集 cars 的 schema 各个字段的
printSchema(cars)root
|-- mpg: double (nullable = true)
|-- cyl: double (nullable = true)
|-- disp: double (nullable = true)
|-- hp: double (nullable = true)
|-- drat: double (nullable = true)
|-- wt: double (nullable = true)
|-- qsec: double (nullable = true)
|-- vs: double (nullable = true)
|-- am: double (nullable = true)
|-- gear: double (nullable = true)
|-- carb: double (nullable = true)从本地 JSON 文件创建 DataFrame
path <- file.path(Sys.getenv("SPARK_HOME"), "examples/src/main/resources/people.json")
peopleDF <- read.json(path)
printSchema(peopleDF)root
|-- age: long (nullable = true)
|-- name: string (nullable = true)peopleDFSparkDataFrame[age:bigint, name:string]showDF(peopleDF)+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+peopleDF 转成 Hive 中的表 people
createOrReplaceTempView(peopleDF, "people")调用 sql 传递 SQL 语句查询数据,启动 sparkR.session 时,设置 enableHiveSupport = TRUE,就是执行不出来,报错,不知道哪里配置存在问题
teenagers <- SparkR::sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
show(people)Error in handleErrors(returnStatus, conn) :
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.io.IOException: (null) entry in command string: null chmod 0733 F:\tmp\hive;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:106)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:214)
at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:114)
at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:102)
at org.apache.spark.sql.internal.SharedState.globalTempViewManager$lzycompute(SharedState.scala:141)
at org.apache.spark.sql.internal.SharedState.globalTempViewManager(SharedState.scala:136)
at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anonfun$2.apply(HiveSessionStateBuilder.scala:55)
at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anonfun$2.apply(HiveSessionStateBuilder.scala:55)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.gl调用 collect 函数执行查询,并将结果返回到本地 data.frame 类型
teenagersLocalDF <- collect(teenagers)查看数据集 teenagersLocalDF 的属性
print(teenagersLocalDF)最后,关闭 SparkSession 会话
sparkR.session.stop()