3.8 Spark 与 R 语言
3.8.1 sparklyr
Spark 依赖特定版本的 Java、Hadoop,三者之间的版本应该要相融。
在 MacOS 上配置 Java 环境,注意 Spark 仅支持 Java 8 至 11,所以安装指定版本的 Java 开发环境
# 安装 openjdk 11
brew install openjdk@11
# 全局设置 JDK 11
sudo ln -sfn /usr/local/opt/openjdk@11/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk-11.jdk
# Java 11 JDK 添加到 .zshrc
export CPPFLAGS="-I/usr/local/opt/openjdk@11/include"
export PATH="/usr/local/opt/openjdk@11/bin:$PATH"配置 R 环境,让 R 能够识别 Java 环境,再安装 rJava 包
# 配置
sudo R CMD javareconf
# 系统软件依赖
brew install pcre2
# 安装 rJava
Rscript -e 'install.packages("rJava", type="source")'最后安装 sparklyr 包,以及 Spark 环境,可以借助 spark_install() 安装 Spark,比如下面 Spark 3.0 连同 hadoop 2.7 一起安装。
install.packages('sparklyr')
sparklyr::spark_install(version = '3.0', hadoop_version = '2.7')也可以先手动下载 Spark 软件环境,建议选择就近镜像站点下载,比如在北京选择清华站点
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgz,此环境自带 R 和 Python 接口。为了供 sparklyr 调用,先设置 SPARK_HOME 环境变量指向 Spark 安装位置,再连接单机版 Spark。
# 排错 https://github.com/sparklyr/sparklyr/issues/2827
options(sparklyr.log.console = FALSE)
# 连接 Spark
library(sparklyr)
library(ggplot2)
sc <- spark_connect(
master = "local",
# config = list(sparklyr.gateway.address = "127.0.0.1"),
spark_home = Sys.getenv("SPARK_HOME")
)
# diamonds 数据集导入 Spark
diamonds_tbl <- copy_to(sc, ggplot2::diamonds, "diamonds")做数据的聚合统计,有两种方式。一种是使用用 R 包 dplyr 提供的数据操作语法,下面以按 cut 分组统计钻石的数量为例,说明 dplyr 提供的数据操作方式。
library(dplyr)
# 列出数据源下所有的表 tbls
src_tbls(sc)
diamonds_tbl <- diamonds_tbl %>%
group_by(cut) %>%
summarise(cnt = n()) %>%
collect另一种是使用结构化查询语言 SQL,这自不必说,大多数情况下,使用和一般的 SQL 没什么两样。
library(DBI)
diamonds_preview <- dbGetQuery(sc, "SELECT count(*) as cnt, cut FROM diamonds GROUP BY cut")
diamonds_preview## cnt cut
## 1 21551 Ideal
## 2 13791 Premium
## 3 4906 Good
## 4 1610 Fair
## 5 12082 Very Good# SQL 中的 AVG 和 R 中的 mean 函数是类似的
diamonds_price <- dbGetQuery(sc, "SELECT AVG(price) as mean_price, cut FROM diamonds GROUP BY cut")
diamonds_price## mean_price cut
## 1 3457.542 Ideal
## 2 4584.258 Premium
## 3 3928.864 Good
## 4 4358.758 Fair
## 5 3981.760 Very Good
library(ggplot2)
library(data.table)
diamonds <- as.data.table(diamonds)
diamonds[,.(mean_price = mean(price)), by = .(cut)]## cut mean_price
## 1: Ideal 3457.542
## 2: Premium 4584.258
## 3: Good 3928.864
## 4: Very Good 3981.760
## 5: Fair 4358.758将结果数据用 ggplot2 呈现出来
ggplot(diamonds_preview, aes(cut, cnt)) +
geom_col() +
theme_minimal()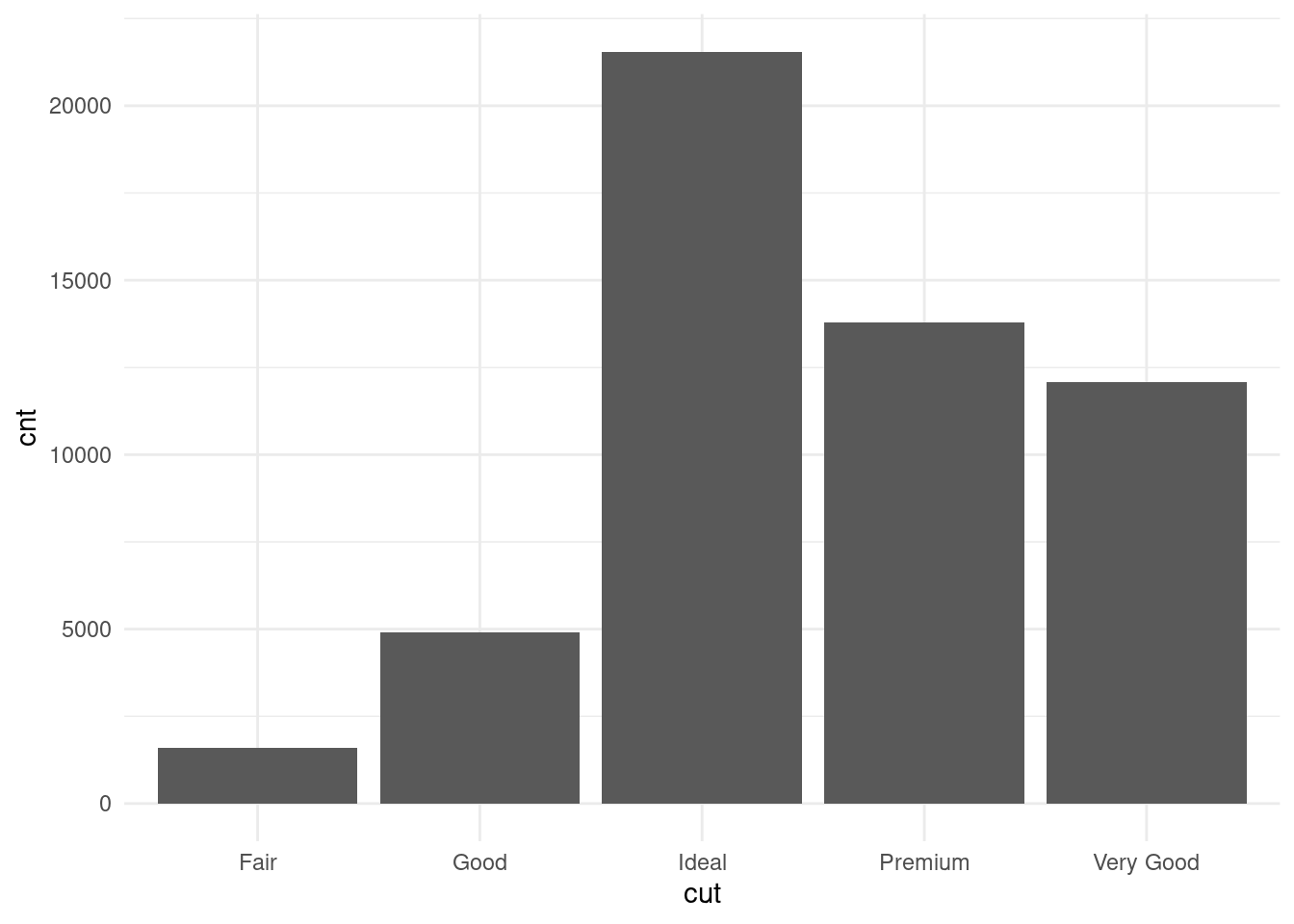
diamonds 数据集总共 53940 条数据,下面用 BUCKET 分桶抽样,将原数据随机分成 1000 个桶,取其中的一个桶,由于是随机分桶,所以每次的结果都不一样,解释详见https://spark.apache.org/docs/latest/sql-ref-syntax-qry-select-sampling.html
diamonds_sample <- dbGetQuery(sc, "SELECT * FROM diamonds TABLESAMPLE (BUCKET 1 OUT OF 1000) LIMIT 6")
diamonds_sample## carat cut color clarity depth table price x y z
## 1 0.60 Ideal F VVS2 62.0 55 2822 5.37 5.40 3.34
## 2 0.77 Ideal E SI2 60.7 55 2834 6.01 5.95 3.63
## 3 0.70 Very Good D VS2 63.1 56 2985 5.62 5.69 3.57
## 4 0.76 Very Good E VS2 61.0 58 3111 5.88 5.93 3.60
## 5 1.00 Good J VS2 62.0 61 3835 6.36 6.45 3.97
## 6 1.01 Good H SI1 64.0 58 4191 6.37 6.31 4.06将抽样的结果用窗口函数 RANK() 排序,详见 https://spark.apache.org/docs/latest/sql-ref-syntax-qry-select-window.html
窗口函数 https://www.cnblogs.com/ZackSun/p/9713435.html
diamonds_rank <- dbGetQuery(sc, "
SELECT cut, price, RANK() OVER (PARTITION BY cut ORDER BY price) AS rank
FROM diamonds TABLESAMPLE (BUCKET 1 OUT OF 1000)
LIMIT 6
")
diamonds_rank## cut price rank
## 1 Fair 4480 1
## 2 Fair 4600 2
## 3 Good 605 1
## 4 Good 3139 2
## 5 Good 3465 3
## 6 Good 4588 4LATERAL VIEW 把一列拆成多行
https://liam.page/2020/03/09/LATERAL-VIEW-in-Hive-SQL/ https://spark.apache.org/docs/latest/sql-ref-syntax-qry-select-lateral-view.html
创建数据集
# 先删除存在的表 person
dbGetQuery(sc, "DROP TABLE IF EXISTS person")
# 创建表 person
dbGetQuery(sc, "CREATE TABLE IF NOT EXISTS person (id INT, name STRING, age INT, class INT, address STRING)")
# 插入数据到表 person
dbGetQuery(sc, "
INSERT INTO person VALUES
(100, 'John', 30, 1, 'Street 1'),
(200, 'Mary', NULL, 1, 'Street 2'),
(300, 'Mike', 80, 3, 'Street 3'),
(400, 'Dan', 50, 4, 'Street 4')
")查看数据集
dbGetQuery(sc, "SELECT * FROM person")## id name age class address
## 1 100 John 30 1 Street 1
## 2 200 Mary NA 1 Street 2
## 3 300 Mike 80 3 Street 3
## 4 400 Dan 50 4 Street 4行列转换 https://www.cnblogs.com/kimbo/p/6208973.html,LATERAL VIEW 展开
dbGetQuery(sc,"
SELECT * FROM person
LATERAL VIEW EXPLODE(ARRAY(30, 60)) tabelName AS c_age
LATERAL VIEW EXPLODE(ARRAY(40, 80)) AS d_age
LIMIT 6
")## id name age class address c_age d_age
## 1 100 John 30 1 Street 1 30 40
## 2 100 John 30 1 Street 1 30 80
## 3 100 John 30 1 Street 1 60 40
## 4 100 John 30 1 Street 1 60 80
## 5 200 Mary NA 1 Street 2 30 40
## 6 200 Mary NA 1 Street 2 30 80日期相关的函数 https://spark.apache.org/docs/latest/sql-ref-functions-builtin.html#date-and-timestamp-functions
# 今天
dbGetQuery(sc, "select current_date")## current_date()
## 1 2023-05-25# 昨天
dbGetQuery(sc, "select date_sub(current_date, 1)")## date_sub(current_date(), 1)
## 1 2023-05-24# 本月最后一天 current_date 所属月份的最后一天
dbGetQuery(sc, "select last_day(current_date)")## last_day(current_date())
## 1 2023-05-31# 星期几
dbGetQuery(sc, "select dayofweek(current_date)")## dayofweek(current_date())
## 1 5最后,使用完记得关闭 Spark 连接
spark_disconnect(sc)3.8.2 SparkR
if (nchar(Sys.getenv("SPARK_HOME")) < 1) {
Sys.setenv(SPARK_HOME = "/opt/spark/spark-3.0.1-bin-hadoop2.7")
}
library(SparkR, lib.loc = c(file.path(Sys.getenv("SPARK_HOME"), "R", "lib")))
sparkR.session(master = "local[*]", sparkConfig = list(spark.driver.memory = "2g"))SparkR 要求 Java 版本满足:大于等于8,而小于12,本地 MacOS 安装高版本,比如 oracle-jdk 16.0.1 会报不兼容的错误。
Spark package found in SPARK_HOME: /opt/spark/spark-3.1.1-bin-hadoop3.2
Error in checkJavaVersion() :
Java version, greater than or equal to 8 and less than 12, is required for this package; found version: 16.0.1sparkConfig 有哪些参数可以传递
| Property Name | Property group | spark-submit equivalent |
|---|---|---|
spark.master |
Application Properties | --master |
spark.kerberos.keytab |
Application Properties | --keytab |
spark.kerberos.principal |
Application Properties | --principal |
spark.driver.memory |
Application Properties | --driver-memory |
spark.driver.extraClassPath |
Runtime Environment | --driver-class-path |
spark.driver.extraJavaOptions |
Runtime Environment | --driver-java-options |
spark.driver.extraLibraryPath |
Runtime Environment | --driver-library-path |
将 data.frame 转化为 SparkDataFrame
faithful_sdf <- as.DataFrame(faithful)SparkDataFrame
head(faithful_sdf)查看结构
str(faithful_sdf)